

Amazon Aurora Limitless Database powers petabyte-scale applications with millions of writes per second. Today, hundreds of thousands of customers use Amazon Aurora, a fully managed MySQL- and PostgreSQL-compatible relational database that provides the performance and availability of commercial databases at up to one-tenth the cost. These organizations rely on Amazon Aurora Serverless v2 to power their applications because it is capable of scaling to support hundreds of thousands of transactions in a fraction of a second. As it scales, it adjusts capacity up and down in fine-grained increments to provide the right amount of database resources for the application. However, there are some use cases, such as online gaming and financial transaction processing, with workloads that need to process and manage hundreds of millions of global users, handle millions of transactions, and store petabytes of data. Today, these organizations must scale horizontally by splitting data into smaller subsets and distributing them across multiple distinct database instances in a process known as “sharding,” which requires months—or even years—of upfront developer effort to build custom software that routes requests to the correct instance or makes changes across multiple instances. Organizations also need to continuously monitor database activity and adjust capacity, which can be time-consuming and impact availability. The ongoing maintenance effort for these workloads is high, as organizations need to coordinate routine maintenance operations—such as adding a column to a table, taking consistent backups across all compute instances, or applying upgrades and patches—and constantly tune and balance the load across multiple instances. As a result, organizations need ways to automatically scale their applications beyond the limits of a single database without spending time building their scaling solutions.
Amazon Aurora Limitless Database scales to millions of write transactions per second and manages petabytes of data while maintaining the simplicity of operating inside a single database. Amazon Aurora Limitless Database automatically distributes data and queries across multiple Amazon Aurora Serverless instances based on a customer’s data model, eliminating the need to build custom software to route requests across instances. As compute or storage requirements increase, Amazon Aurora Limitless Database automatically scales resources vertically within serverless instances and horizontally across instances to meet workload demand, providing customers with consistently high performance while saving them months or years of effort in building custom software to scale their databases. Maintenance operations and changes can be made in a single database and automatically applied across instances, eliminating the need for managing routine tasks across dozens, or even hundreds, of database instances manually.
Amazon Aurora read replicas allow you to increase the read capacity of your Aurora cluster beyond the limits of what a single database instance can provide. Now, Aurora Limitless Database scales write throughput and storage capacity of your database beyond the limits of a single Aurora writer instance. The compute and storage capacity that is used for Limitless Database is in addition to and independent of the capacity of your writer and reader instances in the cluster.
With Limitless Database, you can focus on building high-scale applications without having to build and maintain complex solutions for scaling your data across multiple database instances to support your workloads. Aurora Limitless Database scales based on the workload to support write throughput and storage capacity that, until today, would require multiple Aurora writer instances.
The architecture of Amazon Aurora Limitless Database
Limitless Database has a two-layer architecture consisting of multiple database nodes, either transaction routers or shards.
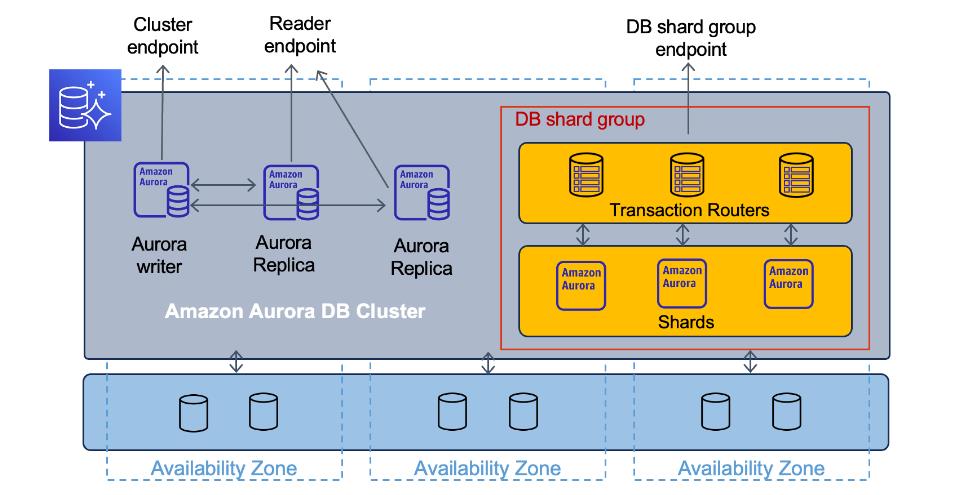

Transaction routers maintain metadata about where data is stored, parse incoming SQL commands and send those commands to shards, aggregate data from shards to return a single result to the client, and manage distributed transactions to maintain consistency across the entire distributed database. All the nodes that make up your Limitless Database architecture are contained in a DB shard group. The DB shard group has a separate endpoint where your access your Limitless Database resources.
Getting started with Aurora Limitless Database
To get started with a preview of Aurora Limitless Database, you can sign up today and will be invited soon. The preview runs in a new Aurora PostgreSQL cluster with version 15 in the AWS US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions.
As part of the creation workflow for an Aurora cluster, choose the Limitless Database compatible version in the Amazon RDS console or the Amazon RDS API. Then you can add a DB shard group and create new Limitless Database tables. You can choose the maximum Aurora capacity units (ACUs).
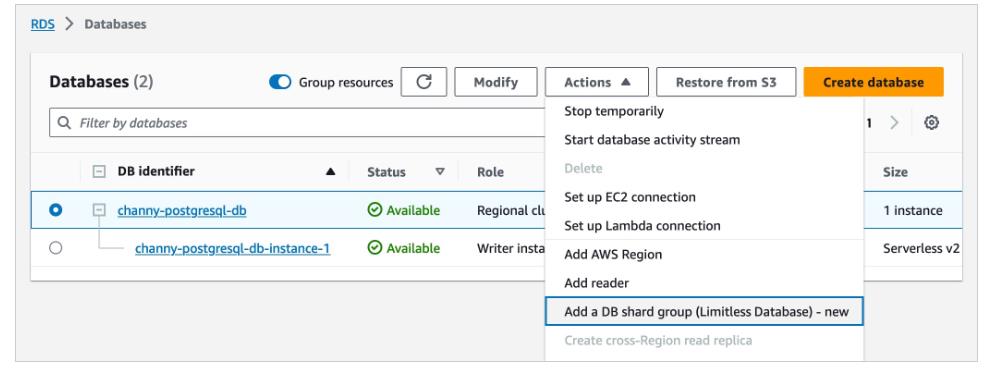

After the DB shard group is created, you can view its details on the Databases page, including its endpoint.
To use Aurora Limitless Database, you should connect to a DB shard group endpoint, also called the limitless endpoint, usingpsql or any other connection utility that works with PostgreSQL.
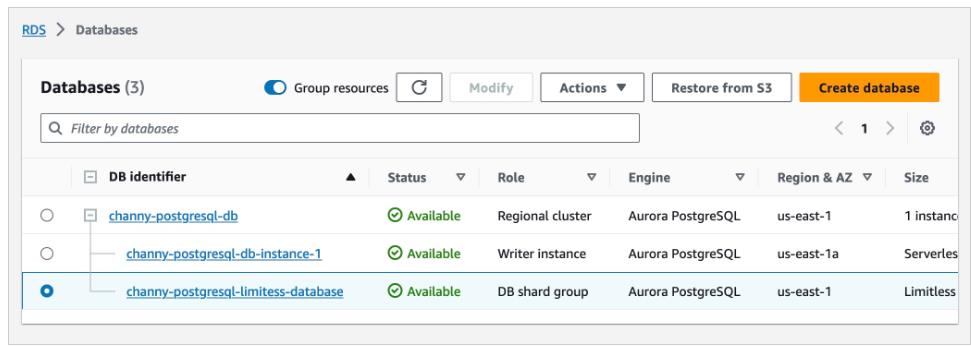

There will be two types of tables that contain your data in Aurora Limitless Database:
- Sharded tables – These tables are distributed across multiple shards. Data is split among the shards based on the values of designated columns in the table, called shard keys.
- Reference tables– These tables have all their data present on every shard so that join queries can work faster by eliminating unnecessary data movement. They are commonly used for infrequently modified reference data, such as product catalogs and zip codes.
Once you have created a sharded or reference table, you can load massive data into Aurora Limitless Database and manipulate data in those tables using the standard PostgreSQL queries.
Amazon ElastiCache Serverless
Amazon ElastiCache Serverless makes it faster and easier to create a cache and instantly scale to meet application demand—without needing to provision, plan for, or manage capacity
Organizations building applications store frequently accessed data in caches to improve application response times and reduce database costs. These customers use open source, in-memory data stores like Redis and Memcached for caching because of their high performance and scalability. To simplify the process of building and running a cache, AWS offers Amazon ElastiCache, a fully managed Redis- and Memcached-compatible service that is used by hundreds of thousands of customers today for real-time, cost-optimized performance. Today, Amazon ElastiCache scales to hundreds of terabytes of data and hundreds of millions of operations per second with microsecond response times, and organizations use it to deploy highly available, mission-critical applications across multiple Availability Zones. While many organizations appreciate the fine-grained configuration options Amazon ElastiCache offers, some companies building a new application or migrating existing workloads want to get started quickly without designing and provisioning cache infrastructure, a process that requires specialized expertise and deep familiarity with application traffic patterns. Organizations also need to constantly monitor and scale their capacity to maintain consistently high performance, or overprovision for peak capacity, which results in excess costs. As a result, they need a solution that can help them manage the underlying infrastructure, making it faster and easier to create and operate a cache.
With Amazon ElastiCache Serverless, customers can now create a highly available cache in under a minute without infrastructure provisioning or configuration. Amazon ElastiCache Serverless eliminates the complex, time-consuming process of capacity planning by continuously monitoring a cache’s compute, memory, and network utilization and instantly scaling vertically and horizontally to meet demand without downtime or performance degradation. With Amazon ElastiCache Serverless, customers no longer need to rightsize or fine-tune their caches. Amazon ElastiCache Serverless automatically replicates data across multiple Availability Zones and provides customers with 99.99% availability for all workloads. Customers only pay for the data they store and the compute their application uses. Amazon ElastiCache Serverless is generally available today for both Redis- and Memcached-compatible deployment options.
Getting started with Amazon ElastiCache Serverless
To get started, go to the ElastiCache console and choose Redis caches or Memcached caches in the left navigation pane. ElastiCache Serverless supports engine versions of Redis 7.1 or higher and Memcached 1.6 or higher.
For example, in the case of Redis caches, chooseCreate Redis cache.

You see two deployment options: either Serverless or Design your own cache to create a node-based cache cluster. Choose the Serverless option, the New cache method, and provide a name.
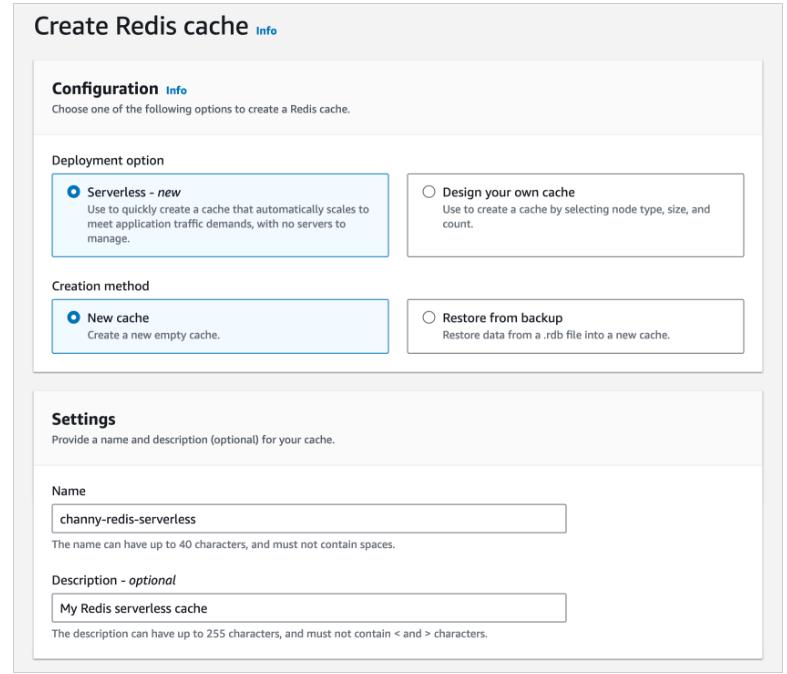

Use the default settings to create a cache in your default VPC, Availability Zones, service-owned encryption key, and security groups. We will automatically set recommended best practices. You don’t have to enter any additional settings.
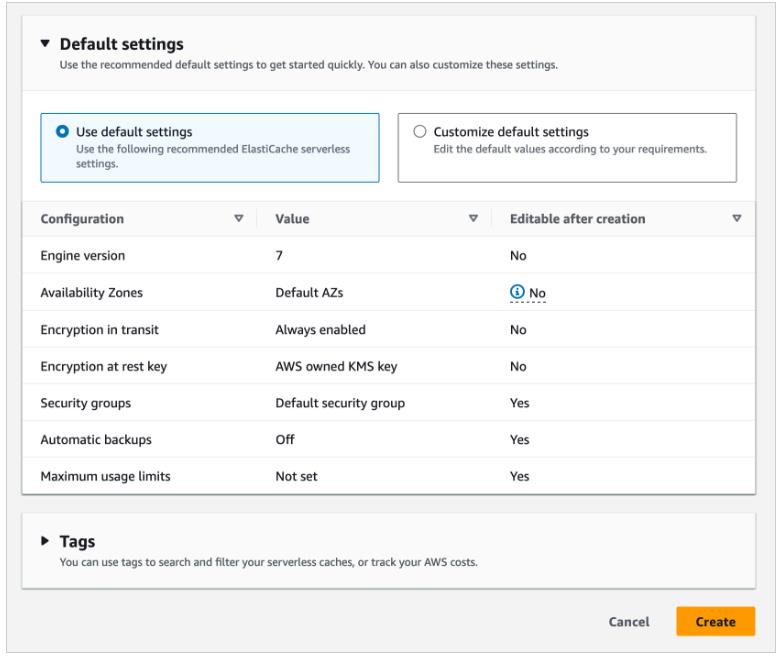
If you want to customize default settings, you can set your own security groups, or enable automatic backups. You can also set maximum limits for your compute and memory usage to ensure your cache doesn’t grow beyond a certain size. When your cache reaches the memory limit, keys with a time to live (TTL) are evicted according to the least recently used (LRU) logic. When your compute limit is reached, ElastiCache will throttle requests, which will lead to elevated request latencies.

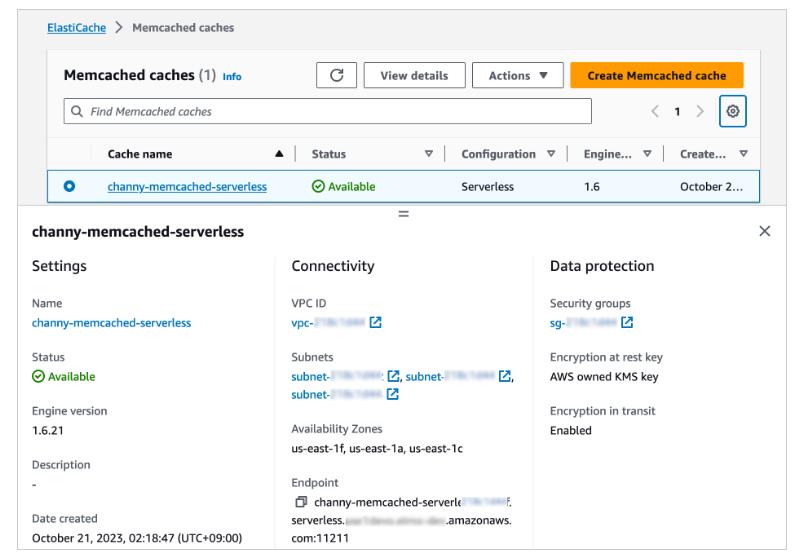
When you create a new serverless cache, you can see the details of settings for connectivity and data protection, including an endpoint and network environment.
Now, you can configure the ElastiCache Serverless endpoint in your application and connect using any Redis client that supports Redis in cluster mode, such as redis-cli.
$ redis-cli -h channy-redis-serverless.elasticache.amazonaws.com –tls -c -p 6379 set x Hello OK get x “Hello”
You can manage the cache using AWS Command Line Interface (AWS CLI) or AWS SDKs. For more information, see Getting started with Amazon ElastiCache for Redis in the AWS documentation.
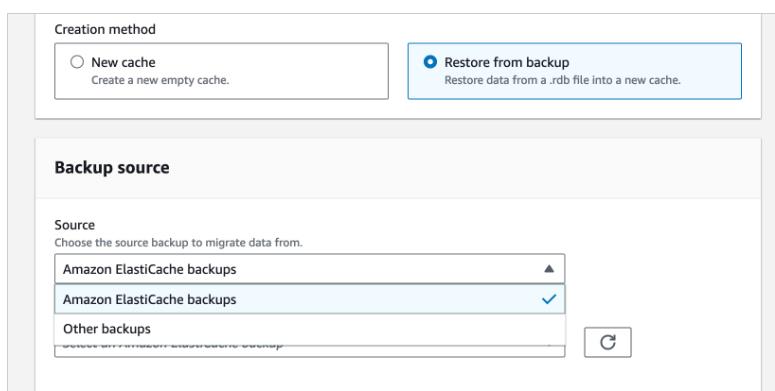
If you have an existing Redis cluster, you can migrate your data to ElastiCache Serverless by specifying the ElastiCache backups or Amazon S3 location of a backup file in a standard Redis rdb file format when creating your ElastiCache Serverless cache.
For a Memcached cache, you can create and use a new serverless cache in the same way as Redis.

If you use ElastiCache Serverless for Memcached, there are significant benefits of high availability and instant scaling because they are not natively available in the Memcached engine. You no longer have to write custom business logic, manage multiple caches, or use a third-party proxy layer to replicate data to get high availability with Memcached. Now you can get up to 99.99 percent availability SLA and data replication across multiple Availability Zones.
To connect to the Memcached endpoint, run the openssl client and Memcached commands as shown in the following example output:
$ /usr/bin/openssl s_client -connect channy-memcached-serverless.cache.amazonaws.com:11211 -crlf
set a 0 0 5
hello
STORED
get a
VALUE a 0 5
hello
END
For more information, see Getting started with Amazon ElastiCache Serverless for Memcached in the AWS documentation.
Scaling and performance
ElastiCache Serverless scales without downtime or performance degradation to the application by allowing the cache to scale up and initiating a scale-out in parallel to meet capacity needs just in time.
To show ElastiCache Serverless’ performance we conducted a simple scaling test. We started with a typical Redis workload with an 80/20 ratio between reads and writes with a key size of 512 bytes. Our Redis client was configured to Read From Replica (RFR) using the READONLY Redis command, for optimal read performance. Our goal is to show how fast workloads can scale on ElastiCache Serverless without any impact on latency.
As you can see in the graph above, we were able to double the requests per second (RPS) every 10 minutes up until the test’s target request rate of 1M RPS. During this test, we observed that p50 GET latency remained around 751 microseconds and at all times below 860 microseconds. Similarly, we observed p50 SET latency remained around 1,050 microseconds, not crossing the 1,200 microseconds even during the rapid increase in throughput.
Things to know
- Upgrading engine version – ElastiCache Serverless transparently applies new features, bug fixes, and security updates, including new minor and patch engine versions on your cache. When a new major version is available, ElastiCache Serverless will send you a notification in the console and an event in Amazon EventBridge. ElastiCache Serverless major version upgrades are designed for no disruption to your application.
- Performance and monitoring – ElastiCache Serverless publishes a suite of metrics to Amazon CloudWatch, including memory usage (BytesUsedForCache), CPU usage (ElastiCacheProcessingUnits), and cache metrics, including CacheMissRate, CacheHitRate, CacheHits, CacheMisses, and ThrottledRequests. ElastiCache Serverless also publishes Amazon EventBridge events for significant events, including cache creation, deletion, and limit updates. For a full list of available metrics and events, see the documentation.
- Security and compliance – ElastiCache Serverless caches are accessible from within a VPC. You can access the data plane using AWS Identity and Access Management (IAM). By default, only the AWS account creating the ElastiCache Serverless cache can access it. ElastiCache Serverless encrypts all data at rest and in-transit by transport layer security (TLS) encrypting each connection to ElastiCache Serverless. You can optionally choose to limit access to the cache within your VPCs, subnets, IAM access, and AWS Key Management Service (AWS KMS) key for encryption. ElastiCache Serverless is compliant with PCI-DSS, SOC, and ISO and is HIPAA eligible.
Now available
Amazon ElastiCache Serverless is now available in all commercial AWS Regions, including China. With ElastiCache Serverless, there are no upfront costs, and you pay for only the resources you use. You pay for cached data in GB-hours, ECPUs consumed, and Snapshot storage in GB-months.
Amazon Redshift Serverless
Next-generation, AI-driven scaling and optimizations in Amazon Redshift Serverless deliver better price-performance for variable workloads
Tens of thousands of customers collectively process exabytes of data with Amazon Redshift every day. Many of these customers rely on Amazon Redshift Serverless, which automatically provisions and scales data warehouse capacity to meet demand based on the number of concurrent queries. While customers enjoy the ease of running analytics workloads of all sizes on Amazon Redshift Serverless without needing to manage data warehouse infrastructure, they would benefit further from the ability to easily adapt to changes in their workloads along additional dimensions, such as the amount of data or query complexity, to achieve consistently high performance while optimizing cost. For example, an organization with normally predictable dashboarding workloads may find that a new regulatory reporting requirement means they need to ingest substantially more data and handle more intensive, complex queries. To address workload changes along all dimensions, while ensuring consistent performance and without disrupting existing workloads, an experienced database administrator would have to spend hours separating the additional workload to a different data warehouse or making multiple, complex manual adjustments. This includes temporarily increasing the resources for data ingestion and new query workloads, pre-computing results for quick data access, organizing data for efficient retrieval, and timing data warehouse management tasks. All of these optimizations need to be done continuously, while managing each individual organization’s priorities for balancing performance and cost, regardless of changes in data volume, query complexity, or more concurrent queries.
With the new AI-driven scaling and optimizations, Amazon Redshift Serverless automatically scales resources up and down across multiple workload dimensions and performs optimizations to meet price-performance targets. Amazon Redshift Serverless uses AI to learn customer workload patterns along dimensions such as query complexity, data size, and frequency and continuously adjusts capacity based on those dynamic patterns to meet customer-specified, price-performance targets. Amazon Redshift Serverless now also proactively adjusts resources based on those customer workload patterns. For example, Amazon Redshift Serverless with AI-driven scaling and optimizations automatically lowers capacity during the day to handle dashboard workloads, but adds just the right amount of required capacity on demand whenever a complex query needs to be processed. Then overnight, Amazon Redshift Serverless proactively increases capacity again to support large data processing tasks without manual intervention. Building on existing self-tuning capabilities, Amazon Redshift Serverless automatically measures and adjusts resources and conducts a cost-benefit analysis to prioritize the best optimization for a given workload. Customers can set their own price-performance targets in the AWS Console, choosing to optimize between cost and performance. Amazon Redshift Serverless with AI-driven scaling and optimizations is available in preview. To learn more, visit aws.amazon.com/redshift/redshift-serverless/.
Serverless dashboard
Login and on the Serverless dashboard page, you can view a summary of your resources and graphs of your usage.
- Namespace overview– This section shows the amount of snapshots and datashares within your namespace.
- Workgroups – This section shows all of the workgroups within Amazon Redshift Serverless.
- Queries metrics – This section shows query activity for the last one hour.
- RPU capacity used – This section shows capacity used for the last one hour.
- Free trial – This section shows the free trial credits remaining in your AWS account. This covers all usage of Amazon Redshift Serverless resources and operations, including snapshots, storage, workgroup, and so on, under the same account.
- Alarms– This section shows the alarms you configured in Amazon Redshift Serverless.
Data backup
On the Data backup tab you can work with the following:
- Snapshots – You can create, delete, and manage snapshots of your Amazon Redshift Serverless data. The default retention period is indefinitely, but you can configure the retention period to be any value between 1 and 3653 days. You can authorize AWS accounts to restore namespaces from a snapshot.
- Recovery points– Displays the recovery points that are automatically created so you can recover from an accidental write or delete within the last 24 hours. To recover data, you can restore a recovery point to any available namespace. You can create a snapshot from a recovery point if you want to keep a point of recovery for a longer time period. The default retention period is indefinitely, but you can configure the retention period to be any value between 1 and 3653 days.
Data access
On the Data access tab you can work with the following:
- Network and security settings – You can view VPC-related values, AWS KMS encryption values, and audit logging values. You can update only audit logging. For more information on setting network and security settings using the console, see Managing usage limits, query limits, and other administrative tasks.
- AWS KMS key – The AWS KMS key used to encrypt resources in Amazon Redshift Serverless.
- Permissions – You can manage the IAM roles that Amazon Redshift Serverless can assume to use resources on your behalf. For more information, see Identity and access management in Amazon Redshift Serverless.
- Redshift-managed VPC endpoints – You can access your Amazon Redshift Serverless instance from another VPC or subnet. For more information, see Connecting to Amazon Redshift Serverless from a Redshift managed VPC endpoint.
Limit
On the Limits tab, you can work with the following:
- Base capacity in Redshift processing units (RPUs) settings – You can set the base capacity used to process your workload. To improve query performance, increase your RPU value.
- Usage limits – The maximum compute resources that your Amazon Redshift Serverless instance can use in a time period before an action is initiated. You limit the amount of resource Amazon Redshift Serverless uses to run your workload. Usage is measured in Redshift Processing Unit (RPU) hours. An RPU hour is the number of RPUs used in an hour. You determine an action when a threshold that you set is reached, as follows:
- Send an alert.
- Log an entry to a system table.
- Turn off user queries.
- Query limits – You can add a limit to monitor performance and limits. For more information about query monitoring limits, see WLM query monitoring rules.
For more information, seeUnderstanding Amazon Redshift Serverless capacity.
Datashares
On the Datashares tab you can work with the following:
- Datashares created in my namespace settings – You can create a datashare and share it with other namespaces and AWS accounts.
- Datashares from other namespaces and AWS accounts – You can create a database from a datashare from other namespace and AWS accounts.
For more information about data sharing, see Data sharing in Amazon Redshift Serverless.
Database performance
On the Database performance tab, you see the following graphs:
- Queries completed per second – This graph shows the average number of queries completed per second.
- Queries duration – This graph shows the average amount of time to complete a query.
- Database connections– This graph shows the number of active database connections.
- Running queries– This graph shows the total number of running queries at a given time.
- Queued queries– This graph shows the total number of queries queued at a given time.
- Query run time breakdown– This graph shows the total time queries spent running by query type.
Resource monitoring
On the Resource monitoring page, you can view graphs of your consumed resources. You can filter the data based on several facets.
- Metric filter – You can use metric filters to select filters for a specific workgroup, as well as choose the time range and time interval.
- RPU capacity used– This graph shows the overall capacity in Redshift processing units (RPUs).
- Compute usage– This graph shows the accumulative usage of Amazon Redshift Serverless by period for the selected time range.
On theDatashares page, you can manage datashares. In my account and From other accounts. For more information about data sharing, see Data sharing in Amazon Redshift Serverless.
