

In the realm of machine learning, the performance of a model heavily relies on the quality and relevance of the features used for training. Feature engineering plays a crucial role in extracting meaningful information from raw data and creating new features that augment the model’s predictive capabilities. This process involves transforming, combining, and selecting features to improve the model’s accuracy, generalization, and robustness. In this blog, we will explore the significance of feature engineering and demonstrate its practical implementation with code examples using Python and popular machine-learning libraries.
What is Feature Engineering?
Feature engineering is the process of transforming raw data into informative features that facilitate the learning process of machine learning algorithms. The right set of features can dramatically impact model performance, whereas poorly engineered features might lead to overfitting or underfitting. By understanding the data’s domain and problem context, feature engineering enables us to extract relevant patterns and relationships, improving model accuracy and interpretability.
Raw data, as it exists, might not be directly usable by machine learning algorithms. Often, it requires preprocessing, and feature engineering serves as a bridge between raw data and actionable insights. During feature engineering, domain knowledge becomes invaluable in selecting appropriate features that capture the underlying patterns in the data.
Importance of Feature Engineering
The following pointers outline the importance of Feature Engineering
Handling Missing Data
Dealing with missing values is a common challenge in real-world datasets. Missing data can be caused by various factors, such as data collection errors or voluntary omissions by users. If not handled properly, missing data can introduce bias into the model. Feature engineering offers various techniques to handle missing data effectively.
One commonly used approach is mean imputation, where missing values in a feature are replaced by the mean of the observed values. This method works well when the missing data is missing completely at random (MCAR). For instance, if we have a dataset with customer information, and some customers did not provide their ages, we can impute the missing ages with the average age of the remaining customers.
Another technique is median imputation, where missing values are replaced by the median of the observed values. Median imputation is preferred when the data has outliers that might influence the mean significantly.
In some cases, it might be better to create an indicator feature that denotes the presence of missing values in a particular feature. This approach allows the model to learn from the missingness pattern and can sometimes yield better results.
Encoding Categorical Variables
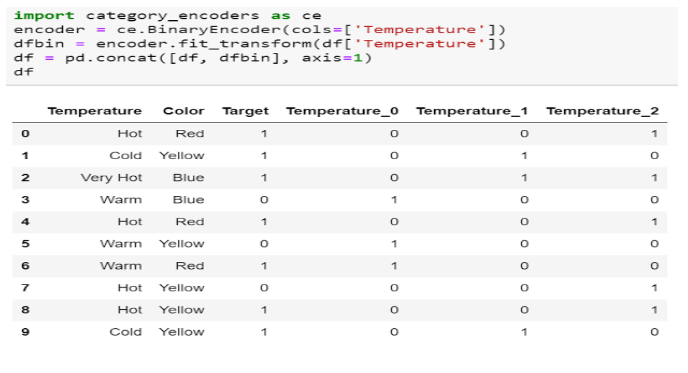

Categorical variables are non-numeric variables that represent different categories or groups. Machine learning algorithms typically require numerical inputs, so categorical variables need to be converted into a suitable numerical format.
Feature engineering provides methods like one-hot encoding, label encoding, and target encoding to effectively convert categorical data into numerical representations.
- One-Hot Encoding: In one-hot encoding, each category is represented as a binary vector, where the corresponding element is set to 1 for the category and 0 for all other categories. For example, if we have a “Gender” feature with categories “Male” and “Female,” one-hot encoding will create two binary features: “Gender_Male” and “Gender_Female.”
- Label Encoding: In label encoding, each category is mapped to an integer value. For example, “Male” might be encoded as 0 and “Female” as 1. Label encoding is suitable for ordinal categorical variables where the order of categories matters.
- Target Encoding: Target encoding involves replacing each category with the mean (or another summary statistic) of the target variable for that category. This method can be useful when dealing with high-cardinality categorical variables.
Creating Interaction Terms
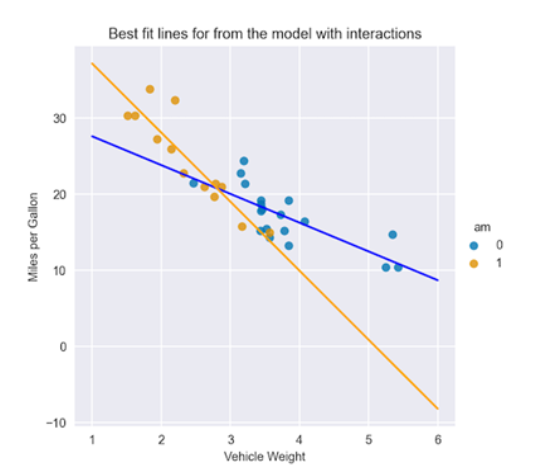

Interaction terms are new features created by combining existing features in a meaningful way. These terms allow the model to capture complex relationships between variables.
For example, in a retail dataset, if we have features “item price” and “quantity sold,” we can create a new feature called “total revenue” by multiplying the two features. This interaction term can provide insights into the relationship between price and quantity in terms of revenue generation.
Interaction terms can also be useful in capturing synergistic effects between variables, which might not be evident when considering each feature in isolation.
Feature Scaling

Feature scaling is a critical step in preparing data for training machine learning models. Many machine learning algorithms rely on distance metrics, and features with large scales might dominate the learning process.
Feature engineering helps to scale numerical features appropriately. Two common techniques for feature scaling are standardization and normalization.
- Standardization (Z-score scaling): Standardization scales the features so that they have a mean of 0 and a standard deviation of 1. This process centres the feature distribution around 0, making it suitable for algorithms that assume a Gaussian distribution of the data.
- Normalization (Min-Max scaling): Normalization scales the features to a specific range, usually [0, 1]. It is particularly useful for algorithms that require features to be on the same scale, such as neural networks and algorithms that use gradient-based optimization.
Dataset and Libraries
To demonstrate the concepts of feature engineering, we can use a dataset related to customer churn prediction.
For this tutorial, we’ll be working with Python and the following libraries:
Python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
Data Preprocessing

Let’s start by loading and preprocessing the dataset.
Python
# Load the dataset
data_url = ‘https://example.com/customer_churn.csv’
df = pd.read_csv(data_url)
# Dropping irrelevant columns
df.drop([‘CustomerID’, ‘Name’, ‘Phone’], axis=1, inplace=True)
# Handling missing values
df.fillna(0, inplace=True)
# One-hot encoding categorical variables
df = pd.get_dummies(df, columns=[‘Gender’, ‘SubscriptionType’], drop_first=True)
# Separating features and target
X = df.drop(‘Churn’, axis=1)
y = df[‘Churn’]
# Splitting the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Feature scaling
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Feature Engineering Techniques:
5.1. Polynomial Features:
Polynomial features help capture nonlinear relationships between variables. We can generate polynomial features using the following code.
Python
from sklearn.preprocessing import PolynomialFeatures
# Creating second-degree polynomial features
poly = PolynomialFeatures(degree=2)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.transform(X_test)
5.2. Feature Interaction:
We can create interaction features by multiplying existing features to discover potential relationships.
Python
# Creating interaction features
X_train_interact = X_train[:, 1] * X_train[:, 3] # Multiplying feature 1 and feature 3
X_test_interact = X_test[:, 1] * X_test[:, 3]
Binning Numeric Data

Binning numerical features can convert continuous data into categorical representations, simplifying complex relationships.
Python
# Binning ‘Age’ feature
bins = [0, 18, 30, 50, np.inf]
labels = [‘Teen’, ‘Young Adult’, ‘Adult’, ‘Senior’]
df[‘AgeGroup’] = pd.cut(df[‘Age’], bins=bins, labels=labels)
df = pd.get_dummies(df, columns=[‘AgeGroup’], drop_first=True)
Model Training and Evaluation

Now, let’s build a logistic regression model and observe the impact of feature engineering on its performance.
Python
# Model training without feature engineering
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_no_engineering = accuracy_score(y_test, y_pred)
# Model training with feature engineering
model_fe = LogisticRegression()
model_fe.fit(X_train_poly, y_train)
y_pred_fe = model_fe.predict(X_test_poly)
accuracy_with_engineering = accuracy_score(y_test, y_pred_fe)
# Model evaluation
print(f”Accuracy without feature engineering: {accuracy_no_engineering}”)
print(f”Accuracy with feature engineering: {accuracy_with_engineering}”)
Conclusion
Feature engineering is a crucial step in the machine learning pipeline that can significantly impact model performance. By carefully selecting, transforming, and combining features, we can extract meaningful information from raw data, improving the model’s predictive capabilities.
Effective feature engineering requires a deep understanding of the data, the problem context, and the algorithms being used. It is not a one-size-fits-all approach and often involves experimenting with different techniques and domain-specific knowledge to achieve optimal model performance.
In this blog, we explored the importance of feature engineering and demonstrated various techniques using Python and scikit-learn. We learned about handling missing data, encoding categorical variables, creating interaction terms, and feature scaling. These techniques can be used in combination or individually to enhance the model’s ability to generalize and make accurate predictions on unseen data.
Remember that feature engineering is an iterative process, and continuous exploration and improvement of features are essential for building accurate and robust models. As the field of machine learning continues to evolve, feature engineering will remain a fundamental aspect of the data science workflow.
