

Introduction
Chatbots are not an exception to the rise of AI-powered products like virtual assistants, image and video recognition, automation tools, and language translation. These bots are computer developed programs that are able to comprehend and respond to natural languages like human conversations. Chatbots are frequently used to automate numerous business operations and to provide customer support on corporate websites.
In this blog, we’ll be using NLP to develop our own custom chatbot from the ground up that you can use as your personal assistant. Are you excited yet? Let’s get started!
How NLP Enables Chatbots to Understand Human Language
Natural language processing (NLP) is a discipline of AI with which a machine can comprehend and interpret human language, such as text or speech.
NLP enables chatbots to understand the context of the message and provide us with meaningful and human-like natural responses to the user commands, rather than pre-defined outputs.
Prerequisites
To follow along with this tutorial, you should have a basic understanding of the following:
- Latest version of Python installed
- Python fundamentals like functions, control structures, loops and conditionals
- Hands-On knowledge of sci-kit library
- General understanding of NLP and techniques like named entity recognition, tokenization, and part-of-speech tagging.
- Command line interface (CLI) to run commands and execute scripts
- IDE installed (VS Code or Pycharm)
What we’re building
For this tutorial, we will be building MedBot, your friendly health assistant. The user can communicate with this bot to receive tailored information on meditation and mental health to support their wellness journey. The goal of this chatbot is to deliver precise responses based on the dataset we enter.
NLP comes with some robust tools like spaCy, NLTK, Google Cloud Natural Language API, Amazon Comprehend, and Stanford CoreNLP.
Choosing the right tool is an important step in NLP projects, which depends on the requirements of your app, and ultimately the features you want to implement. Here is a detailed guide to get you started if you want to learn more about various NLP tools and techniques.
For this chatbot, we will be using a popular open-source tool called NLTK.
Setting up the development environment
Now that we have a basic understanding of our chatbot, it’s time to start writing the code.
You must first set up your development environment before you can begin creating your Medbot with NLTK. Here are the general steps you’ll need to follow:
If you haven’t already, you’ll need to install Python on your system to follow along. You can get the latest version of Python from the official website.
To see if Python has been successfully installed on your computer, type the following command in the terminal:
python –version
Installing dependencies
Once you have Python installed, the next step is to install a few dependencies that are required for our chatbot.
| import nltk import numpy as np import random import string import re import urllib.request import bs4 as bs |
numpy: A library for numerical computing in Python.
random: A module to generate random numbers.
string: A module to perform common string operations.
bs4: A library to parse HTML and XML documents.
re: A module to work with regular expressions.
urllib.request: A module to open URLs and download data from the web.
Building the Chatbot
We are using the BeautifulSoup library to retrieve data. For MedBot, we will use this Wikipedia article that offers some content on meditation.
1. Extracting the Text
In NLP, we begin by building a corpus, which is like a repository of text data used to further train the model.
We will start by implementing a function called get_article_text() that extracts all the text from the paragraphs in the specified URL and returns it as a string. urllib.request.urlopen() will fetch the HTML content and deliver it to the soup object, which will parse the content in a much cleaner way.
The function will return the text variable, which will contain all the paragraph content in a string format.
| from bs4 import BeautifulSoup
def get_article_text(url): |
2. Text Preprocessing
After retrieving the text content, we must preprocess it to remove any irregularities such as spaces and other special characters that may produce irrelevant results.
Text preprocessing is a key stage in natural language processing because it allows us to clean and transform raw data into a format that machine learning models can easily analyze.
Here we have defined a function clean_article_text(), which uses the re() module to clean the text by removing square brackets and their contents and replacing multiple whitespace characters with a single space character:
| def clean_article_text(text): cleaned_text = re.sub(r’\[[0-9]*\]’, ‘ ‘, text) cleaned_text = re.sub(r’\s+’, ‘ ‘, cleaned_text) return cleaned_text article_content = clean_article_text(article_text) |
Tokenization
Next we need to tokenize or split the text into smaller portions, essentially words or sentences using the sent_tokenize() and word_tokenize() functions, using the NLTK library. The function get_text_content() returns a tuple that contains a list of sentences and a list of words.
Without tokenization, the text would simply be a string of characters with no discernible meaning.
| nltk.download(‘punkt’) def get_text_content(text): sentences = nltk.sent_tokenize(text) words = nltk.word_tokenize(text) return (sentences, words) article_para, article_words = get_text_content(article_content) |
Text Normalization and Lemmatization
Following tokenization, we will lemmatize the text using NLTK’s WordNetLemmatizer in the final phase of text preprocessing.
Lemmatization helps to reduce a word to its simplest form for easier analysis; for example, “cats” becomes “cat”, “running” becomes “run”, “chasing” returns “chase”, and so on.
This is beneficial for NLP tasks like text classification and sentiment analysis, where the context of the text is important.
| nltk.download(‘wordnet’) wn_lemmatizer = nltk.stem.WordNetLemmatizer() remove_punctuation = dict((ord(punctuation), None) for punctuation in string.punctuation) def lemmatize_tokens(tokens): return [wn_lemmatizer.lemmatize(token) for token in tokens] def get_processed_text(content): processed_text = content.lower().translate(remove_punctuation) tokens = nltk.word_tokenize(processed_text) lemmatized_tokens = lemmatize_tokens(tokens) return lemmatized_tokens |
3. Generating Chatbot Responses
Greeting the User
Our text data is ready at this point. We will now construct a function get_response() that generates a response based on the input greeting.
This function returns a random response from the GREETING_RESPONSES list when the user’s input matches any of the keywords in GREETING_INPUTS.
| GREETING_INPUTS = (“heya”, “hi”, “hello”, “what’s up”, “peace be with you”, “morning!”, “good morning”, “good evening”, “namaste”) GREETING_RESPONSES = [“hey”,“Greetings, my friend.”, “hey how’s it going?”, “I am doing well. Thank you for asking.”, “How may I assist you today?”, “Peace be with you as well.”, “hello, how are you doing”, “hello”, “Welcome, I am good, and you?”, “Namaste.”] def get_response(greet): for token in greet.split(): if token.lower() in GREETING_INPUTS: return random.choice(GREETING_RESPONSES) |
Responding to User Input
To respond to other user inputs, we will utilize cosine_similarity() and TFidfVectorizer from the scikit-learn library.
cosine_similarity() calculates the cosine similarity between two vectors, text in this case, while TFidfVectorizer will be used to convert a set of words into a TF-IDF feature matrix.
These methods are often used for retrieving information, text classification, and clustering.
| from sklearn.metrics.pairwise import cosine_similarity from sklearn.feature_extraction.text import TfidfVectorizer |
We then define a function generate_response(), which generates a response to the input text using cosine similarity to compare it with the existing text data in the article_para list we defined earlier. The stop_words parameter is set to english, specifying that common English stop words like ‘um’, ‘the’, ‘and’, ‘but’ should be removed from the text.
TFidfVectorizer is used to tokenize and vectorize the input text of the article_para list. The cosine similarity scores are sorted in ascending order, with the second highest score representing the similarity of the input text to the closest matched text. If the function’s second highest similarity score is zero, it returns a failed response that it did not understand the input text.
Otherwise, the function responds with the closest matched text.
| def generate_response(text_input): response = ” article_para.append(text_input) vectorize_text = TfidfVectorizer(tokenizer=get_processed_text, stop_words=‘english’) text_output = vectorize_text.fit_transform(article_para) cosine_similarity_output = cosine_similarity(text_output[-1], text_output) similarity_index = cosine_similarity_output.argsort()[0][-2] matched_output = cosine_similarity_output.flatten() matched_output.sort() vector_output = matched_output[-2] if vector_output == 0: response = response + “I’m sorry, I didn’t understand what you said. Could you please rephrase?” return response else: response = response + article_para[similarity_index] return response |
Now we will write the main logic of the chatbot. When the user enters some greeting text, this chatbot will generate a greeting using the get_response() function. When the user begins to interact with the chatbot to input queries related to meditation, it will utilize the generate_response() function to create a response based on the user input.
Finally, the user input is removed from the article_para list to prevent the chatbot from adding user inputs into the responses data.
If the user types “bye”, the chatbot prints a goodbye message and exits the loop.
| print(“Hello, I am your friend MedBot. You can ask me any questions about meditation:”) while True: text_input = input().lower() if text_input == ‘bye’: print(” *MedBot*: Goodbye! May you find inner peace.”) break if text_input in [‘thanks’, ‘great help!’, ‘thanks a lot’, ‘thank you’]: print(” *MedBot*: You’re welcome! Glad I could be of any help to you today.”) continue greeting_response = get_response(text_input) if greeting_response: print(” *MedBot*: “ + greeting_response) else: response = generate_response(text_input) article_para.remove(text_input) print(” *MedBot*: “ + response) |
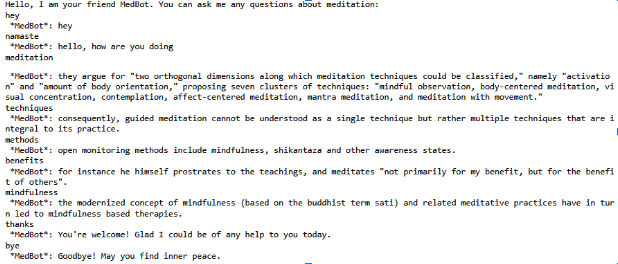
Here’s an example of how our MedBot works:

Conclusion
In this tutorial, we learned how to create our own chatbot, implementing some NLP techniques in the process.
Of course, this was only a primer to get you started. Once you understand the fundamentals of NLP and its techniques, you can create a chatbot that is much more responsive and engaging. You can further improve your chatbot over time to meet the evolving needs of your audience using fine-tuned models.
